Here is my (extended) family tree:
Everyone in the tree shares at least one common ancestor and at least one common descendant. This makes my family tree a
lattice, an important mathematical structure. While lattices are often presented in abstract algebraic form, they have a simple graphical representation called a
Hasse diagram, which is similar to a family tree.
Because most lattice theory assumes a strong background in algebra, I think the results are not as well known as they should be. I hope to give a sampling of some lattices here, and a hint of their power.
What are Lattices?
A lattice is a structure with two requirements:
- Every two elements have a "least upper bound." In the example above, this is the "most recent common ancestor".
- Every two elements have a "greatest lower bound." In the example above, this is the "oldest common descendant".
Note that the bound of some elements can be themselves; e.g. the most recent common ancestor of me and my mother is my mother.
Lattices are a natural way of describing
partial orders, i.e. cases where we sometimes know which element came "first", but sometimes don't. For example, because the most recent common ancestor of my mother and myself is my mother, we know who came "first" - my mother must be older. Because the least upper bound of my mother and my father is some third person, we don't know which one is older.
Shopping Carts
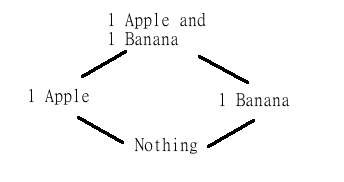
Here's an example of four different ways to fill your shopping cart:
The lines between two sets indicates preference: one apple is better than nothing, but one apple and one banana is even better than one apple. (Note that the arrows aren't directed, because every relation has a dual [e.g. the "better than" relation has a dual relation "worse than]. So whether you read the graph top-to-bottom or bottom-to-top, it doesn't really matter. By convention, things on the bottom are "less than" things on the top.)
Now, some people might prefer apples to bananas, and some might prefer bananas to apples, so we can't draw any lines between the "one apple" and the "one banana" situations. Nonetheless, we can still say that you prefer having both to just one, so this order is pretty universal.
The least upper bound in this case is "the worst shopping cart which is still preferred or equal to both things" (doesn't quite roll of the tongue, does it?), and the greatest lower bound is "the best shopping cart which is still worse than or equal to both things". Because these two operations exist, this means that shopping carts (or rather the goods that could be in shopping carts) make up a lattice.
A huge swath of economic and ethical problems deal with preferences which can be put into lattices like this, which makes lattice theory a powerful tool for solving these problems.
Division
This is a more classical "math" lattice:
Here a line between two integers indicates that the lower one is a factor of the higher one. The least upper bound in this lattice is the
least common multiple (lcm) and the greatest lower bound is the
greatest common divisor (gcd, some people call this the "greatest common factor").
The greatest common divisor of 4 and 10 is 2, and the least common multiple of 2 and 3 is 6.
Again we don't have a total ordering - 2 isn't a factor of 3 or vice versa - but we can still say something about the order.
An important set of questions about lattices deal with operations which don't change the lattice structure. For example, $k\cdot\gcd(x,y)=\gcd(kx,ky)$, so multiplying by an integer "preserves" this lattice.
 Multiplying the lattice by three still preserves the divisibility relation.
Multiplying the lattice by three still preserves the divisibility relation.
A lot of facts about gcd/lcm in integer lattices are true in all lattices; e.g. the fact that $x\cdot y=\gcd(x,y)\cdot \text{lcm}(x,y)$.
Boolean Logic
Here is the simplest example of a lattice you'll probably ever see:
Suppose we describe this as saying "False is less than True". Then the operation AND becomes equivalent to the operation "min", and the operation OR becomes equivalent to the operation "max":
- A AND B = min{A, B}
- A OR B = max{A, B}
Note that this holds true of more elaborate equations, e.g. A AND (B OR C) = min{A, max{B, C}}. In fact, even more complicated
Boolean algebras are lattices, so we can describe complex logical "gates" using the language of lattices.
Everything is Addition
I switch now from examples of lattices to a powerful theorem:
[Holder]: Every operation which preserves a lattice and doesn't use "incomparable" objects is equivalent to addition.1
The proof of this is fairly complicated, but there's a famous example which shows that multiplication is equivalent to addition: logarithms.
The relevant fact about logarithms is that $\log(x\cdot y)=\log(x)+\log(y)$, meaning that the problem of multiplying $x$ and $y$ can be reduced to the problem of adding their logarithms. Older readers will remember that this trick was used by
slide rules before there were electronic calculators.
Holder's theorem shows that similar tricks exist for any lattice-preserving operation.
Everything is a Set
Consider our division lattice from before (I've cut off a few numbers for simplicity):
Now replace each number with the set of all its factors:
We now have another lattice, where the relationship between each node is set inclusion. E.g. {2,1} is included in {4,2,1}, so there's a line between the two. You can see that we've made an equivalent lattice.
This holds true more generally: any lattice is equivalent to another lattice where the relationship is set inclusion.
2
Max and Min Revisited
Consider the following statements from various areas of math:
$$\begin{eqnarray}
\max\{x,y\} & = & x & + & y & - & \min\{x,y\} &\text{ (Basic arithmetic)} \\
P(x\text{ OR } y) & = & P(x) & + & P(y) & - & P(x\text{ AND } y) & \text{ (Probability)} \\
I(x; y) & = & H(x) & + & H(y) & - & H(x,y) & \text{ (Information theory)} \\
\gcd(x,y) & = & x & \cdot & y & \div & \text{lcm}(x,y) & \text{ (Basic number theory)} \\
\end{eqnarray}$$When laid out like this, the similarities between these seemingly disconnected areas of math is obvious - these results all come from the basic lattice laws. It
turns out that merely assuming a lattice-like structure for probability results in the sum, product and Bayes' rule of probability, giving an argument for the Bayesian interpretation of probability.
Conclusion
The problem with abstract algebraic results is that they require an abstract algebraic explanation. I hope I've managed to give you a taste of how lattices can be used, without requiring too much background knowledge.
If you're interested in learning more: Most of what I know about lattices comes from Glass'
Partially Ordered Groups, which is great if you're already familiar with group theory, but not so great otherwise. Rota's
The Many Lives of Lattice Theory gives a more technical overview of lattices (as well as an overview of why everyone who doesn't like lattices is an idiot) and J.B. Nation has some good
notes on lattice theory, both of which require slightly less background. Literature about specific uses of lattices, such as in
computer science or
logic, also exists.
Footnotes
- Formally, every l-group with only trivial convex subgroups is l-isomorphic to a subgroup of the reals under addition. Holder technically proved this fact for ordered groups, not lattice-ordered groups, but it's an immediate consequence.
- By "equivalent" I mean l-isomorphic.